

🤖 Opportunities in generative AI
🤖 Opportunities in generative AI
+ How to start a consumer generative AI startup

Hey hey 👋,
Welcome to the 715 founders and investors who have joined the Consumer Startups family since the last send! If you haven’t subscribed, join thousands of other consumer founders and investors by subscribing here:
Today’s Consumer Startups is brought to you by… Usage AI
Does your company use AWS?
Usage AI helps you reduce your AWS bill by 57% in less than 5 minutes through cloud contract arbitrage. You’ll get long-term AWS pricing but on a month-to-month basis.
No extra dev work or expensive on-demand prices ever again.
Usage covers your monthly spend with Elastic RIs, meaning that you get the best discount but with no lock-in. And Usage is contractually obligated to buy back your unused RIs, meaning that you won't be stuck paying for unused commitments.
Join companies like Imgur and Deel who trust Usage to save on cloud costs. Get your first three months free when you signup with the code “CONSUMERSTARTUPS”.
Last time, I wrote about some emerging consumer AI startups that caught my attention. Since that post, I have gotten many replies from the community wanting to learn more about the space, specifically B2C opportunities in AI.
One of the most significant breakthroughs in AI in the past decade is arguably generative AI, a topic that has seemingly taken over the entire startup universe in the past few months. In layman’s terms, it’s an AI program that can generate some output content, such as text, image, video, speech, or code from some input. For example, I was able to generate the picture below by typing ‘A robot writing on a computer with a dog, sitting in a garden, green, oil painting’ in Midjourney, a text-to-image AI program.

Many startups have already started to monetize this technology at scale. Jasper, an AI writing tool for marketers, just announced its $125M Series A at a $1.5B valuation and is expected to make $90M in revenue by the end of 2022. Many indie builders have also found success with building with generative AI. One of the legendary indie hackers, Pieter Levels (who also goes by @levelsio on Twitter), reached $5K MRR with its AI interior design generator platform interiorai.com in just a few weeks.


Generative AI has the potential to be another massive platform that will propel the next generation of startups. We are hitting an inflection point where you no longer need tons of money or be a Stanford AI Ph.D. to create a high-quality AI-powered application. This new technological advancement will unlock tons of entrepreneurship opportunities for consumer founders. For this post, I teamed up with my good friend, Markus Mak, to dive into this topic. We will cover the following:
The history of generative AI
Top generative AI models and their capabilities
Generative AI ideas for consumer founders
Risks and opportunities
Let’s jump right in.
History of Generative AI
Before discussing some of the opportunities in the consumer space, let’s first understand what generative AI is and how we got to where we are today.
Generative AI refers to AI models’ ability to create something new. Generative AI is powered by deep learning, which is a technique that underlies most artificial intelligence these days, ranging from self-driving cars to recommendation engines. Generative AI is propelled by two major advancements in deep learning research: Generative Adversarial Network (GAN) and Generative Pre-trained Transformer (GPT).
Here’s all you have to know about the history of Generative AI.
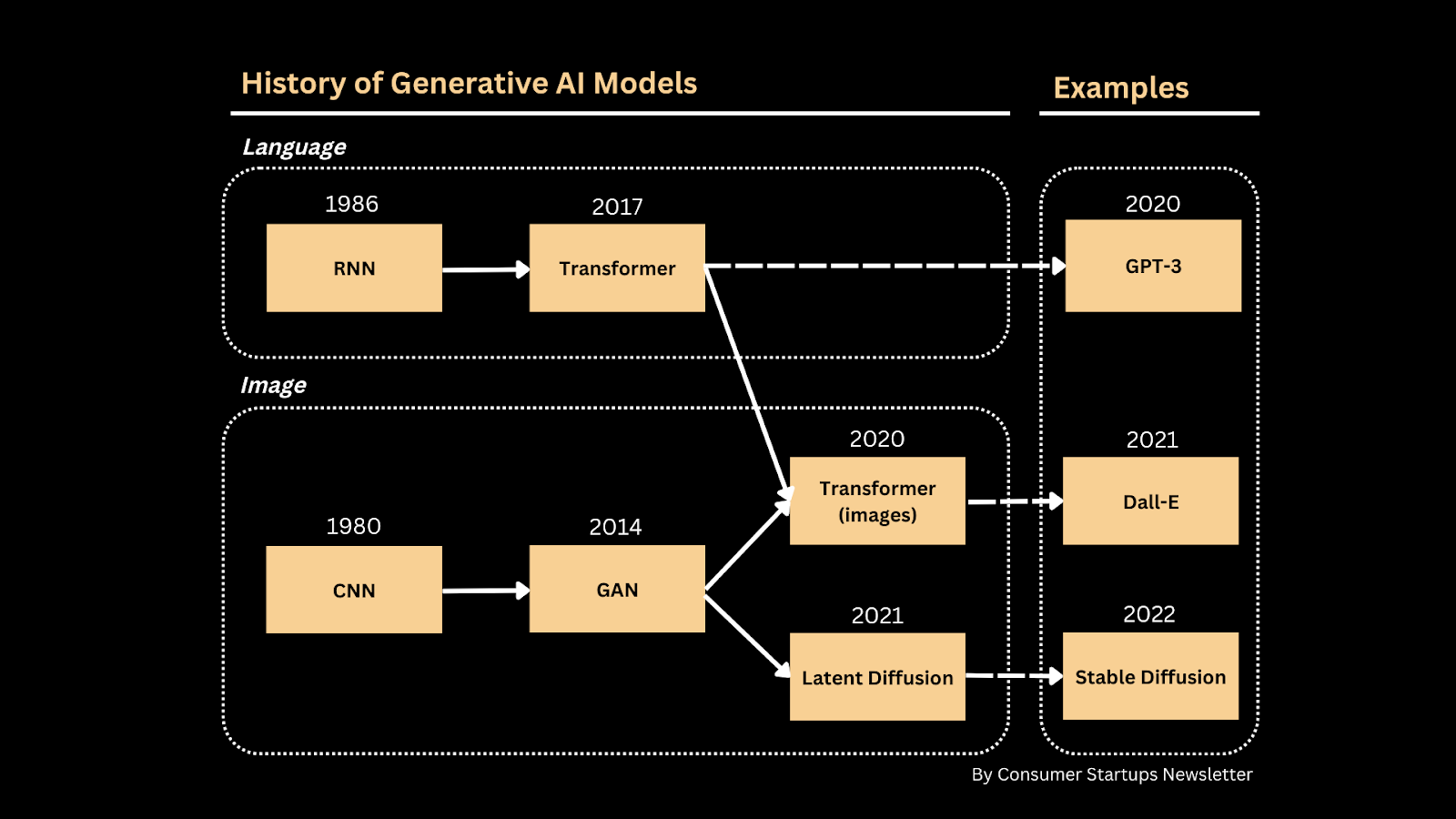
Before 2014, CNN, the best image model at the time, could only do classification tasks, i.e. it could tell you whether a picture is a dog but couldn’t create a dog image on its own. Old language models, such as RNN, struggled with remembering the context when generating long sentences or paragraphs.
In 2014, Ian Goodfellow proposed the GAN after dreaming up the idea of pitting a neural network against another. GANs gifted computers with the ability to create hyper-realistic images, such as those images of people who don’t exist. In 2017, the Google Brain team introduced a revolutionary transformer architecture for language in Attention is All You Need, outperforming RNN. This is because RNN processes sentences word by word while transformers process sentences together, allowing transformers to remember the context better when generating long paragraphs. Transformers are now used to power most state-of-the-art models, such as GPT-3.
The biggest problem with GAN is that it can only generate images with limited variety. To solve the problem, some models utilize the transformer architecture but extend their applications to image data, such as Dall-E (2021) and Dall-E 2 (2022). Some other models, known as latent diffusion models (LDM), leverage another class of models called diffusion models and combine them with GAN and transformers. This is the underlying architecture that powers models like Stable Diffusion.
Why now?
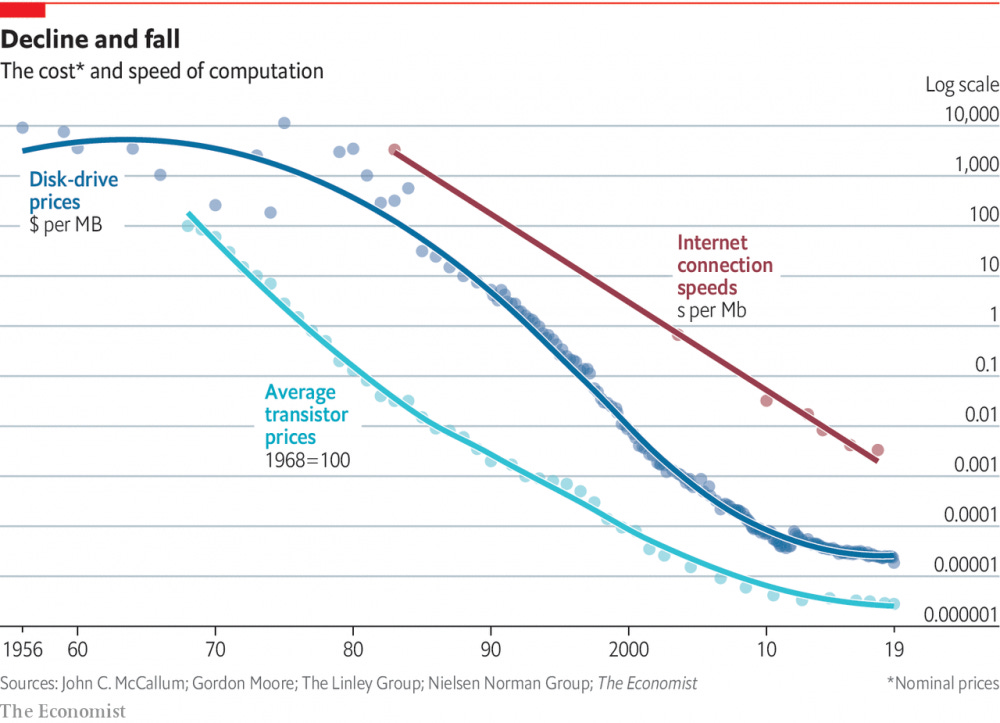
Low computing cost: the computing cost has dropped significantly over time, making the training cost and usage of large generative models affordable for mass adoption. New models such as Stable Diffusion further lower the hardware requirements to run the model such that everyone can do it with their personal computers.
High-quality models: these large-scale generative models, like GPT-3, perform very well across a wide range of tasks; some can even perform previously unimaginable tasks, such as creating an AI-generated podcast between Joe Rogan and Steve Jobs.
Ease of implementation: since these large-scale generative models are pre-trained and are for general purposes, they can be used straight out of the box. Model users only have to run the model by supplying inputs to the model, which can be achieved with a handful of lines of code. Most models also have a no-code option on their website as a lightweight option for users to play around with.
Generative AI landscape and opportunities

The opportunities within generative AI are immense. There are four main segments based on the output form factor of the generative AI model - text, image, speech, and video. There are numerous applications associated with each one.
For example - with generative text, marketers can use it to create contextually relevant blog posts based on some keywords to save time. With generative images, interior designers can use the technology to generate design ideas for their clients to augment their own creativity. With generative speech, newsletter writers can convert a written post into a podcast, unlocking additional distribution channels. With generative videos, teachers can create video content from images or text, making learning more engaging for students.
For the next part, we will discuss each of these four output form factors, unpacking the leading AI models that companies are using along with their capabilities, different applications in the market today, and startup opportunities for consumer founders.
(1) Text

AI Models
Language is the most fundamental mode of communication that transcends space and time and permeates the fabric of our everyday lives. The launch of GPT-3 in 2020 shocked the public with the machine's ability to generate hyper-realistic human-like texts, drawing attention to the potential of these large-scale language models. Some state-of-the-art models include:
GPT-3 is developed by Open AI with 175 billion parameters and costs $12M to train. New users get $18 in free credit for the first three months to experiment with the API. Afterward, the entry model costs $0.0004 per 1k tokens, which is approximately 750 words. You can access it via its web app or its API.
EleutherAI is an open-source alternative to GPT-3, meaning it’s free to use! Its GPT-Neo-20B has 20 billion parameters and has a similar implementation to GPT-3. GPT-J-6B uses a different model architecture with 6 billion parameters. You can access it via its web app or API.
Bloom by Hugging Face is the largest open-sourced multilingual language model with 46 natural languages and 13 programming languages trained with 176 billion parameters. You can access it via its web app or API.
AI Capabilities
We divide the capabilities of language models into three levels. The first-order capabilities are the fundamental features of most models, including text completion, insertion, and editing. Second-order capabilities are some of the more dynamic use cases or applications of the first-order capabilities, including chat, Q&A, translation, parsing data, and classification, such as sentiment analysis. Third-order capabilities refer to the concept of ‘embedding’ – using the result of a language model as an input to other machine learning algorithms to create even more complex use cases. This opens up more advanced abilities, such as smart search and recommendation engines.
Startups in the Space
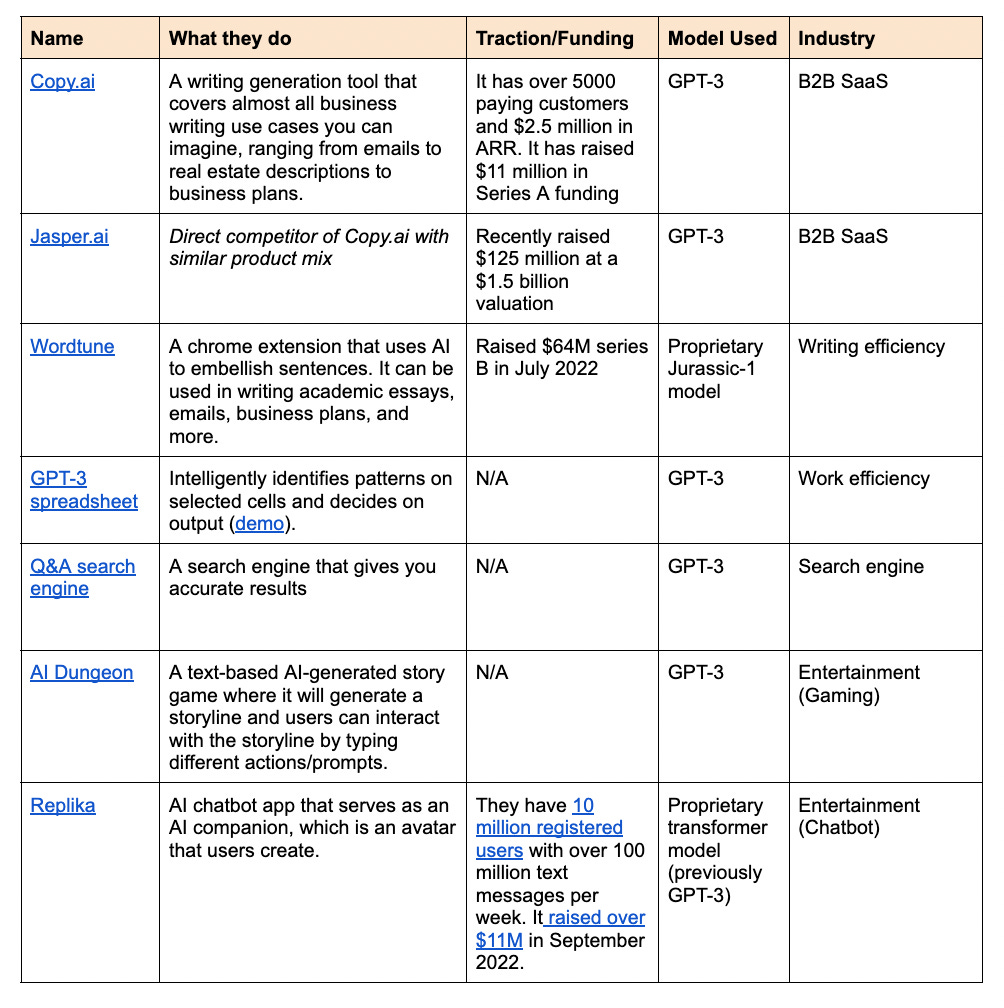
Opportunities
There are three main types of writing:
Fact-based writings that are descriptive or narrative
Creative writing, such as writing a story
Reasoning writing that focuses on developing complex logic
The current models are capable of creating most fact-based writing (Q&A search engine, Wordtune), followed by basic creative and reasoning writing capabilities accompanied by human intervention for quality control (e.g. Copy.ai, AI Dungeon, GPT-3 Spreadsheet). As the models mature, there will be more opportunities to replace higher reasoning and creativity-demanding tasks.
Some ideas below:
Marketer: AI-generated articles with different marketing focus/optimizations (e.g. SEO optimized articles)
Writer: vertically optimized writing assistance focusing on niche use cases such as homework assistance/correction, blogging, creative writing, grant writing, and more
Entertainment: script/story writing, interactive and fully customized storyline for each audience
Knowledge assistant: summarize knowledge, generate new knowledge, automatic knowledge map builder…
(2) Image

AI Models
Image generation has generated a significant amount of buzz lately, propelled by OpenAI’s public release of Dall-E 2. Besides Dall-E 2, there are several world-class AI models used to generate images, including Midjourney and Stable Diffusion. Each of these could be useful depending on the use case.
Dall-E 2 is an AI model released by the leading AI research lab, OpenAI. It attracted over 100K beta users even before the September public release. First-time users get 50 free credits to try it out and can buy more for commercial usage. You can access it via its web app or API
Midjourney is an AI model created by an independent AI lab, Midjourney. It currently operates using a Discord bot, but it already has an active community of 1M+ people. Users can generate images based on a discord command. Like Dall-E 2, you have a certain amount of free usage limits, and then you have to pay
Stable diffusion is an open-source AI model released by Stability AI. It is free to access and does not have as many restrictions as Midjourney and Dall-E 2. However, it only has basic safety features (e.g. preventing offensive content)
AI capabilities
Depending on the model, there are different capabilities. The first common capability is text-to-image. You can generate an image based on a text description, such as “an astronaut lounging in a tropical resort in space, pixel art.” The second capability is image editing. You can replace or add certain elements to an image from a text caption. The third common one is image variant generation. By uploading an image, the AI can create variants of the same image.
Below is an illustration of how you can put these three together using Dall-E 2:

Startups in the space
Several startups are making waves in this space by leveraging this image-based generative technology.
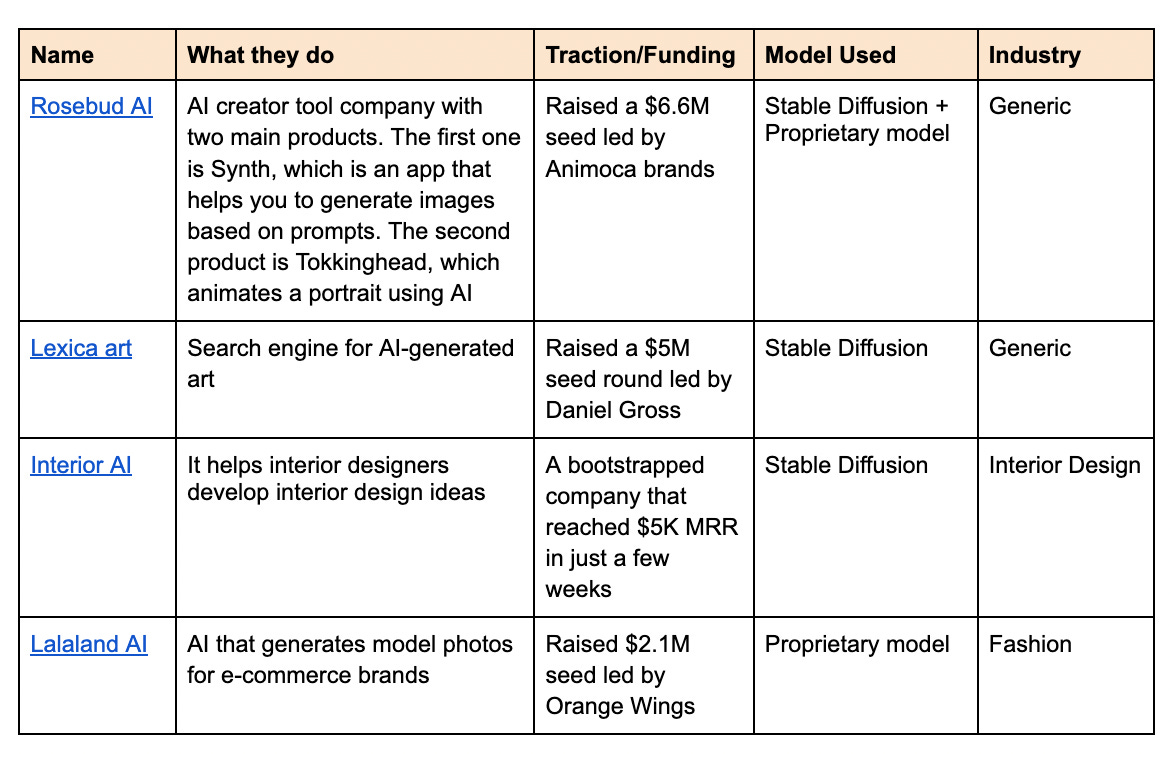
Opportunities
The AI generative image space is relatively blank. We have not seen many major commercial successes just yet. However, we expect to see more vertical creator tools that focus on serving niche communities.
Here are some ideas:
Product designers: AI version of Dribbble. Tools or plugins that help product designers to find design ideas for their features
Graphic designers: AI asset creation and editing tool. Making it easy to create, edit, and create variants of a specific icon or image asset.
Photographers: AI-powered image editing platform to reduce the time it takes to edit professional-grade photos.
Creators: cover image generator. Generate a cover image based on an article.
Marketers: 10x easier ways to create social media assets
(3) Speech
AI models
Even though most speech AI models today focus on transcription(e.g. OpenAI’s whisper), there are still many models that enable text-to-speech(TTS). Hugging Face offers 200+ open-source TTS models for different languages, from English to Ukrainian. They have a user-friendly interface where you can also test out the speech outputted by the model.
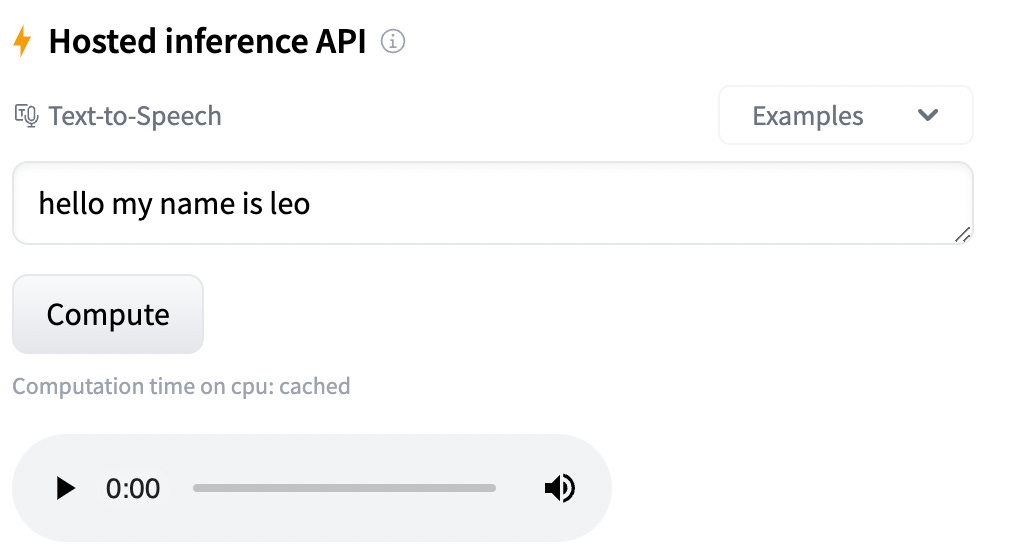
One of the most liked and downloaded models from Hugging Face TTS is the Fastspeech2 model released by researchers at Meta AI.
AI capabilities
The core capability of TTS is to convert text into different voices. However, when combined with other models, such as AI speech-to-text transcription and transcription, there could be many more possibilities.
Startups in the space
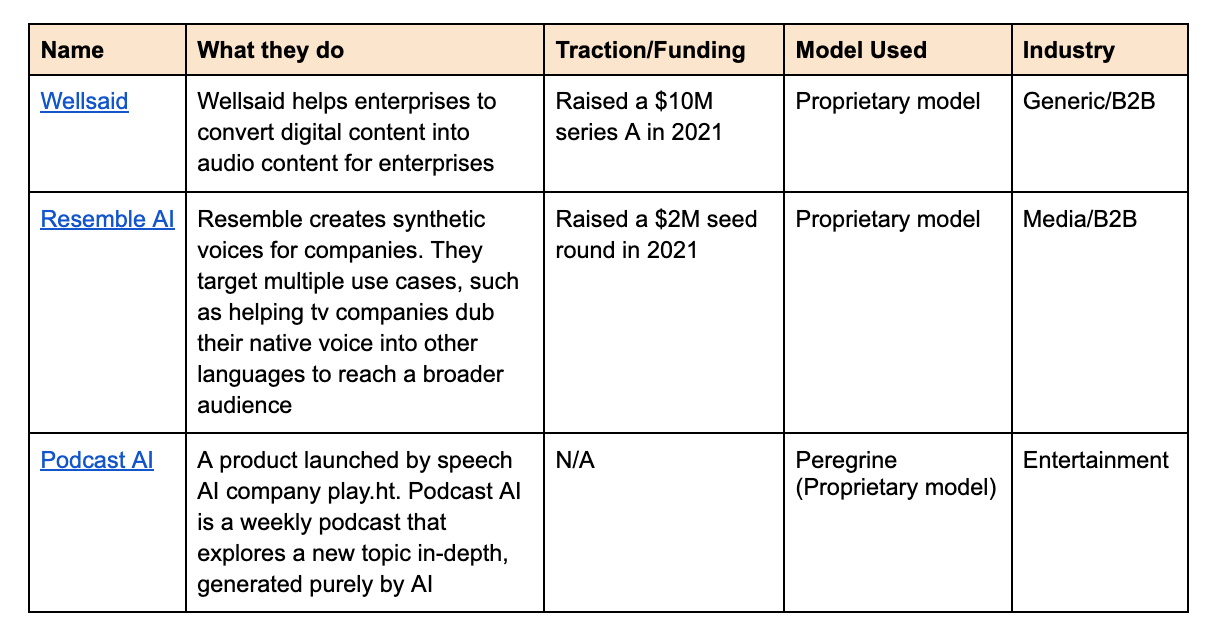
Opportunities
Speech generation can be helpful in many settings.
Here are some ideas:
Real-time audio translation: make it easier to have audio conversations in different languages in real time. Language is no longer a barrier, no matter where you live.
Podcast generation: generate a podcast from an essay. It can be especially useful for newsletter writers or bloggers who are looking to expand distribution channels but don’t have the bandwidth.
Nostalgic chatbot: exchange audio messages with a bot that sounds like a late family member.
Language buddy bot: the best way to learn a language is to speak it. It would be cool to practice a language by exchanging audio messages with a language buddy bot.
(4) Video

AI models
Video generation AI is still in its infancy due to the significantly greater complexity compared to the aforementioned form factors. To quote from a recent post by Mark Zukerberg, “it's much harder to generate video than photos because beyond correctly generating each pixel, the system also has to predict how they'll change over time.”
The model that received the most media attention recently is Meta’s Make-A-Video, which has text-to-video capability. However, it cannot generate clips that are longer than 5 seconds with resolutions higher than 768x768 pixels at 16 frames per second. Currently, the only publicly available text-to-video model is CogVideo, which also has many limitations, such as the length of the video. The model Phenaki, recently released by Google Brain in September 2022, can generate longer coherent stories with different concepts. We would expect more mature infrastructure to pop up in the near future.
AI capabilities
Mainly basic, short, low-resolution video generation since the technology is still in the early phases of research.
Startups in the space
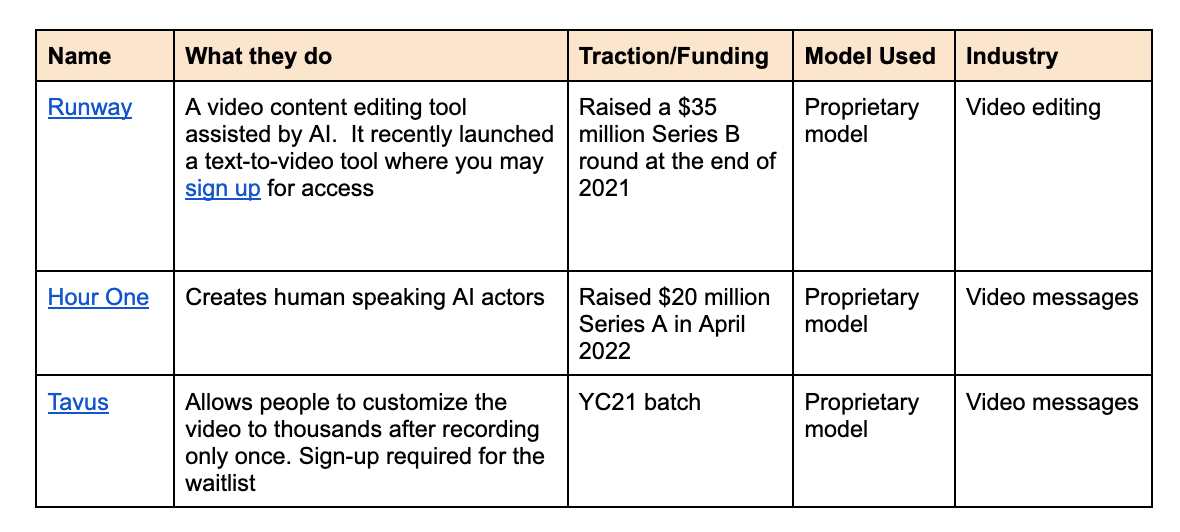
Opportunities
Marketers: create videos that optimize your marketing objectives and metrics, e.g. virality, clickthrough, …
Entertainment: huge opportunities in the entertainment industry once computers can generate hyper-realistic videos, e.g. generate movies/shows
Risks and opportunities
Risks
“With great power comes great responsibility.” Generative technology is immensely powerful, and with misuse, it can cause great harm to society. AI research companies like OpenAI are doing a good job of including safety features in their released models, such as filtering out discriminatory content; however, many AI models today are open-sourced and are not equipped with needed safety features. They are subject to misuse, and there have already been instances where generative technologies are being used to distribute misinformation and harmful content.
Opportunities
There are many new opportunities with the rise of generative technology. Generative technology has the potential to increase efficiency for marketers, improve creativity for designers, enable more distribution channels for content creators, and create new opportunities for many, many more.
With companies like Jasper, we are just starting to see what is possible with generative technology. We have reached a point where not only are the models getting really good, but they are also accessible and affordable. With just a few lines of code and some training data, you can start unlocking the potential of generative AI. The key now is to find real problems that can be solved with generative technology.
Given how easy and cheap generative AI capabilities are, it is important to consider how your idea builds a moat (e.g. data, network effects, switching cost…) to maintain long-term competitiveness. James Currier from NFX has a great 4-question framework for thinking about what is a good generative tech idea:
How can it have network effects where every new user adds value to every other user?
How can it embed itself in a business or someone’s life so they don’t want to stop using it in the long run? This is Jasper’s job in 2023 to figure out.
Where are the hyper-local data sets for your AI model that you can own and maintain your data network effects despite competition coming in later?
Where can you plug into existing workflows, a browser, or an app?
It’s time to build!

Useful generative AI articles to check out:
Generative AI: A Creative New World by Sequoia Capital - Link
Generative Tech Begins by NFX - Link
Who Wins the AI Value Chain by Napkin Math - Link
Hugging Face - Link
That’s it for this week! See you soon 👋,
Leo & Markus
Super relevant, and great read.